
 |
|
 |
||||||||||||||||||||||||||||||
|
Rafał T. Prinke Terra rubrica - terra electronica
Wersja 1.0.0 z dnia 12.10.1998 r. ... ale my śmiejemy się z zarozumiałości tych,
którzy sądzą, że dość zwyczajnego wzroku ludzkiego,
aby móc czytać w tych księgach...
Jan Potocki, Rękopis znaleziony
w Saragossie
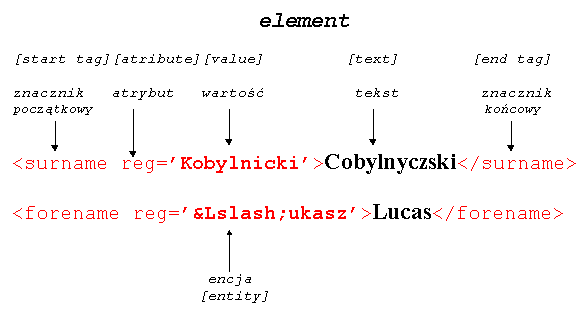
Historia warsztatu humanistyki to - w jedym z możliwych ujęć - historia poszukiwania alinearnego dostępu do tekstu. Czytanie tekstu odbywa się w sposób linearny (sekwencyjny), od początku do końca dzieła czy inskrypcji, natomiast badanie tekstu, jego analiza i porównywanie z innymi tekstami, jest w swej istocie alinearne (niesekwencyjne). Odwiecznym problemem twórców kultury, filozofów, myślicieli religijnych, naukowców - i właściwie wszystkich korzystających z jakichkolwiek dokumentów pisanych - jest możliwość w miarę łatwego i szybkiego dotarcia do właściwych miejsc w tekstach, jak również do ich interpretacji przez samych autorów bądź też wcześniejszych badaczy. Już najstarsze znane zabytki piśmiennictwa sumeryjskiego i egipskiego stosowały metody umożliwiające dodatkowe określanie przynależności poszczególnych słów do ogólniejszych klas, zarówno gramatycznych jak i znaczeniowych. W piśmie sumeryjskim ten sam znak klinowy mógł oznaczać zarówno sylabę (wartość fonetyczną), pojęcie (wartość semantyczną), jak i całą klasę pojęć (wartość klasyfikacyjną) - np. bóstwa, kraje, męskie imiona własne, ptaki, ryby, liczbę mnogą itd. Aby zatem uniknąć wieloznaczności, wprowadzono determinatywy, czyli znaki stawiane przed lub po wyrazach wymagających dodatkowego określenia. Znaków tych nie wymawiano - służyły jedynie uściśleniu znaczenia słów, po których następowały, a więc były informacją metatekstową [1]. W egipskim piśmie hieroglificznym, które być może powstało pod wpływem idei przyniesionej z Sumeru, determinatywy znalazły jeszcze szersze zastosowanie [2]. Z jednej strony spełniały one funkcję wyznaczania granic wyrazów (niczym współczesne spacje), z drugiej natomiast określały znaczenie danego słowa, wyrażonego często jedynie przy pomocy spółgłosek, a nie odrębnych pojęć (jak to ma miejsce w znakach ideograficznych). Podobnie jak w spokrewnionych ze staroegipskim językach semickich, pismo hieroglificzne nie odnotowywało samogłosek, a pojedyncze znaki mogły oddawać jedną, dwie lub trzy spółgłoski. Można to przedstawić w przybliżeniu w ten sposób: RMN<imię męskie> = Roman RMN<kraj> = Rumunia gdzie te same spółgłoski przedstawiają zupełnie inną informację semantyczną. Stosując hieroglify pojedynczych spółgłosek i determinatywy dla zapisania tych samych nazw, otrzymamy:
co jednoznacznie określa sens każdego wyrazu, a tym samym również jego wymowę. Poza determinatywami, pismo egipskie pozwalało również na odróżnienie zastosowania ideogramu od fonogramu. Do tych pierwszych dostawiana była pionowa kreska, podczas gdy na końcu słów zapisanych znakami o wartościach fonetycznych dodawano hieroglif jednej spółgłoski odpowiadający ostatniej spółgłosce w wyrazie. Nie były one oczywiście wymawiane, a jedynie opisywały właściwy tekst. Innym - znacznie lepiej znanym - przykładem adnotacji tekstu w piśmie hieroglificznym jest użycie podłużnego kartusza dla oznaczenia imion władców. Ściśle mówiąc w ten sposób wyróżniane były dwa spośród pięciu imion faraona: imię Syna Ra (czyli właściwe imię urodzeniowe we współczesnym znaczeniu) oraz imię jako Króla Dolnego i Górnego Egiptu. Inne imię - imię Horusa - ujęte było w ramkę zwaną "serekh", symbolizującą pałac królewski. Dzięki temu łatwo było (i nadal jest - nawet nie znając języka egipskiego) odszukać imiona władców na inskrypcjach i w tekstach papirusowych - a więc dotrzeć do poszukiwanej informacji bez potrzeby czytania całego tekstu, czyli w sposób alinearny.
 Leżące u źródeł cywilizacji europejskiej alfabetyczne pismo łacińskie wykształciło, rzecz jasna, zupełnie inne sposoby przekazywania informacji metatekstowych [3]. Oddzielanie wyrazów spacjami, wcięcia akapitowe czy wytłuszczone nagłówki to tylko niektóre oznaczenia formalne - dziś dla nas oczywiste, ale kiedyś stanowiące niezwykle ważną innowację wprowadzoną do pierwotnego scripto continua. Jeszcze istotniejsze z punktu widzenia analizy tekstu było zastosowanie we wczesnym średniowieczu glos interlinearnych, służących objaśnianiu pojedynczych słów, fraz czy całych fragmentów tekstu.  Dopiski takie - po których pozostał do dziś zwrot "czytać między wierszami" - były często wykonywane (podobnie jak ozdobne inicjały czy ważne partie tekstu) inkaustem barwionym czerwoną glinką zwaną terra rubrica dla wyraźniejszego odróżnienia ich przy alinearnym przeszukiwaniu tekstu. Proces ten określano terminem "rubricatio", a z czasem "rubryką" zaczęto nazywać również innego rodzaju dodatkowe informacje stojące poza właściwym tekstem, a zwłaszcza nagłówki zestawień tabularycznych i instrukcje wypełniania formularzy, skąd pochodzi współczesne znaczenie tego słowa [4]. Glosy interlinearne przekształciły się później w tytuły rozdziałów i nagłówki poszczególnych partii tekstu, obecnie powszechnie stosowane. Proces ten najlepiej widać na przykładzie Biblii: trudno byłoby chyba znaleźć współczesne jej wydanie bez śródtytułów streszczających niewielkie fragmenty (rozdziały), na jakie oryginalny jednolity tekst został w ciągu wieków podzielony. Nieco później pojawiły się glosy marginalne, które można jeszcze dziś spotkać w książkach drukowanych [5]. Obok spełniania funkcji wyjaśniających i opisujących tekst, znacznie usprawniały jego przeszukiwanie - sygnalizując zawartość sąsiednich partii tekstu i zwalniając badacza od konieczności czytania całego dzieła.
 Mimo tak znacznego postępu, badacz musiał nadal przeglądać wszystkie karty dzieła (choć nie musiał już ich czytać). Dopiero wprowadzenie rejestrów zawartości (spisów treści), a szczególnie indeksów, zwolniło go od tego trudu i pozwoliło na błyskawiczne dotarcie do właściwego miejsca w tekście - pod warunkiem, jednak, że osoba zestawiająca ów indeks uznała interesujące nas miejsce za warte (czy też godne) odnotowania i umieściła je pod takim hasłem, pod którym będziemy go szukali. Z doświadczenia wiemy, że nie zawsze tak było i nie zawsze jest jeszcze dzisiaj - wystarczy sięgnąć do książki telefonicznej. Rozwiązaniem problemu arbitralności doboru haseł indeksów stały się korkondancje czyli zestawienia wszystkich (a nie tylko wybranych) słów z danego dzieła z odesłaniem do miejsc ich występowania w tekście. Konkordancje Biblii zaczęto zestawiać już od XIII w., ale pierwsza konkordancja tekstu niebiblijnego (dzieł Shakespeare'a) powstała dopiero w 1787 r. Mimo, że idea konkordancji była słuszna, jej praktyczne zastosowanie na szerszą skalę okazało się trudne ze względu na olbrzymi nakład pracy, jakiego wymagała. Wraz z nadejściem ery komputerów osobistych, każdy tekst na nich napisany lub w inny sposób przetworzony na tekst elektroniczny (e-text) stał się samoistną quasi-konkordancją, albowiem błyskawiczne dotarcie do dowolnego słowa czy frazy nie stanowi najmniejszego problemu. Stosunkowo łatwo można też generować tradycyjne konkordancje, a także zestawienia kolokacyjne i kontekstowe. Mimo wszystko, jednak, taki "konkordacyjny" dostęp do tekstu nie może w pełni satysfakcjonowac badacza-humanisty. Najcenniejsze dlań informacje są często zawarte implicite w tekście (aluzje, metafory, figury retoryczne) czy też przekazywane przez jego formę fizyczną (cechy paleograficzne, ubytki, różne ręce) albo układ typograficzny (tytuły rozdziałów, tabulacje, listy). Równolegle do zestawień typu indeksów i konkordancji rozwijały się zatem nadal metody oznaczania takich (i innych) elementów tekstu, kontynuujące tradycje sumeryjsko-egipskich determinatywów i średniowiecznej terra rubrica. Do tej ostatniej nawiązuje czerwona czcionka stosowana powszechnie w wysokiej jakości drukach nawet do XVIII w., natomiast do tej pierwszej - wprowadzenie różnych krojów czcionek na oznaczanie różnych informacji metatekstowych. Współczesna praktyka edytorska posługuje się ustalonymi w ciągu ostatnich dwustu lat konwencjami. Stosowanie ich jest jednak na tyle niejednolite w różnych kręgach językowych (a nawet w różnych wydawnictwach), że często prowadzi do nieporozumień i dyskusji na temat "jedynie słusznych" reguł zapisu informacji metatekstowej, pozwalającej opisać sam tekst w taki sposób, by ułatwić zarówno zrozumienie go, jak i alinearny doń dostęp. Wynika to z braku uświadomienia sobie, że wszelkie, mniej lub bardziej sformalizowane, reguły prezentacji tekstu są jedynie konwencją, której zadaniem ma być przekazanie czytelnikowi dodatkowych informacji o tekście, niemożliwych do wyrażenia przy pomocy samych tylko znaków pisarskich. Wielu z tych konwencjonalnych sposobów opisu tekstu uczymy się wraz z nabywaniem umiejętności czytania i pisania, w związku z czym stają się one - podobnie jak reguły gramatyczne naszego macierzystego języka - funkcją podświadomą. Jednocześnie reguły te podlegają stałej ewolucji i bardzo często trudno jest dziś ustalić dlaczego jakieś słowo czy fraza w druku z XVII wieku zostały złożone kursywą albo frakturą. Niektóre z powszechnie stosowanych elementów opisujących dane metatekstowe w odniesieniu do formalnych części tekstu to:
Sprawa komplikuje się jednak kiedy rozważamy sposoby wyróżniania bardziej szczegółowych elementów tekstowych, takich jak podkreślenia, dialogi, cytaty, zapis bibliograficzny, czy przypisy. Mamy wówczas do czynienia już nie z jedną konwencją i ewentualnymi odstępstwami od niej, ale z całkowicie różnymi konwencjami. Oto jak niektóre z tych pojęć przekazuje się metodami typograficznymi we współczesnych drukach polskich i - dla porównania - angielskich.
Przy takiej rozbieżności nie możemy mieć pewności, że w każdym przypadku właściwie zinterpretujemy informację, jaką autor czy wydawca tekstu chce nam przekazać. Jeżeli będziemy mieli do czynienia z tekstem w języku angielskim drukowanym w Polsce, to wybór konwencji interpretacyjnej stanie się problematyczny. Co więcej, liczba możliwości oznaczania elementów tekstu jest niezwykle uboga - co mamy bowiem do dyspozycji, to zaledwie:
Pomysł umieszczenia informacji metatekstowych w innym miejscu, często odległym od opisywanego fragmentu (początkowo u dołu strony, z czasem również na końcu rozdziału, na końcu książki, a nawet w innym woluminie), pozwolił na znacznie większą swobodę i pełnię wypowiedzi badacza w porównaniu z fizycznymi ograniczeniami objętości glos czy niejednoznacznymi sygnałami przekazywanymi przez zmianę kroju, wielkości lub koloru czcionki. Idea sformalizowanego odsyłacza do innego miejsca w książce pozwoliła na podobne potraktowanie odwołań do innych książek - czyli wprowadzenie przypisów bibliograficznych. Co prawda ścieżka prowadząca badacza od tekstu do informacji metatekstowej wydłużyła się - zamiast po prostu przeczytać glosę obok danego fragmentu, musi przejść do innego miejsca (np. na koniec książki), właściwie odczytać zapis bibliograficzny innej pozycji, odszukać ją (często w bibliotece) i znaleźć odnośny fragment innego tekstu - ale w ten sposób zaczęła powstawać swego rodzaju globalna sieć powiązań międzytekstowych, łącząca całość piśmiennictwa wytworzonego przez ludzkość w ciągu wieków. W przypadku pewnych konwencji stosowanych w przypisach mamy jednak do czynienia z utrudnieniem - a nie ułatwieniem - alinearnego dostępu do tekstu. Kiedy pewne elementy tekstu są wyjaśnione jedynie w przypisach, a nie wyróżnione w druku, to odszukanie ich stanowi istotny problem dla badacza. Trudność tę wzmaga dodatkowo stosowanie małej czcionki w tekście przypisów, a także skróconych i nieprecyzyjnych odsyłaczy bibliograficznych w rodzaju op. cit. Nie mniej ważną rolę w rozwoju sposobów alinearnego dostępu do tekstu odegrała ewolucja materiałów pisarskich i fizycznego nośnika pisma, od glinianej tabliczki i rylca używanych przez starożytnych pisarzy w Mezopotamii i Egipcie, poprzez zwój papirusowy lub pergaminowy i pędzelek, aż po kartę papierową i prasę drukarską albo maszynę do pisania. Przełomowe były zwłaszcza momenty zastąpienia zwoju przez książkę kodeksową (usprawniające fizyczny dostęp do poszukiwanego miejsca w jednym egzemplarzu) i wprowadzenie druku (pozwalające szybko zwielokrotnić tekst bez konieczności żmudnego przepisywania). Przedstawiona powyżej ewolucja metod udostępniania tekstu badaczowi znajduje swoją kulminację i kolejny punkt zwrotny w obecnej rewolucji informatycznej i jej najciekawszym dla humanisty wytworze - tekście elektronicznym. Jak w przypadku każdej rewolucji, przejście od tekstu drukowanego do elektronicznego nie odbywa się bez oporu i krytyki ze strony konserwatywnie nastawionych uczonych, traktujących komputer co najwyżej jako usprawnioną maszynę do pisania. Podobnie było jednak i z wprowadzeniem druku: wielce uczony Johannes Trithemius (1462-1516), opat klasztoru benedyktynów w Sponheim, przewidywał w De laude scriptorum (1492), że druk na papierze nie przyjmie się i jest jedynie tymczasową modą, która nigdy nie wyprze rękopisu pergaminowego, znacznie bardziej trwałego, przygotowywanego z większym pietyzmem i dającego nieporównanie więcej satysfakcji estetycznej w obcowaniu z nim. A jednak w swej kronice klasztoru w Hirsau (1515) wyrażał się już z wielkim uznaniem o sztuce drukarskiej jako ars mirabilis [6]. Cztery wieki później podobne opory wobec wprowadzenia maszyn do pisania miał ksiądz patron Jackowski w Księgarni św. Wojciecha w Poznaniu [7] - co również nie zahamowało ogólnego postępu i dziś nie do pomyślenia jest już oddanie do drukarni rękopisu. Innym przejawem wstrzemięźliwości konserwatystów wobec tekstu elektronicznego jest niechęć do czytania na ekranie komputera, za pośrednictwem naturalnego dlań medium (nie mówiąc już o przetwarzaniu algorytmicznym i programowo wspomaganej analizie), ale drukowanie go każdorazowo na papierze i korzystanie w sposób tradycyjny. Analogicznie postępowali ich poprzednicy w XV wieku: masowe kopiowanie inkunabułów w skryptoriach jest dobrze udokumentowanym zjawiskiem kulturowym z wczesnego okresu upowszechniania druku [8]. Tekst elektroniczny umożliwia stosowanie wszystkich wypracowanych przez wieki sposobów alinearnego docierania do tekstu i do informacji metatekstowej - i to o wiele szybciej i sprawniej. Jak już wspomnieliśmy, tekst elektroniczny jest sam dla siebie konkordancją i częściowo również indeksem. Odszukanie w nim tego, co zawiera explicite - czyli ciągów znaków pisarskich i innych symboli graficznych - nie stanowi najmniejszego problemu. Wykonywanie kopii jest nieporównanie szybsze i łatwiejsze niż w przypadku druku, a jednocześnie praktycznie nic nie kosztuje. Wprowadzanie zmian, poprawek i uzupełnień nie jest ograniczone fizyczną przestrzenią kartki papieru, a nowe wydania moga być publikowane z niczym nieograniczoną częstotliwością. Co więcej, sama analiza tekstu - jego przeszukiwanie, porównywanie jednych partii z innymi, jak również z innymi tekstami - może być w dużym stopniu zautomatyzowana poprzez zaprogramowanie standardowych czynności, na które badacz zwykle poświęca najwięcej czasu, a które komputer wykona błyskawicznie. Ażeby, jednak, program komputerowej analizy tekstu był przydatny dla humanisty, musi rozróżniać wszystkie te elementy tekstu - jego struktury formalnej, znaczeniowej, retorycznej itd. - które humanista chciałby zbadać. Innymi słowy, musi "inteligentnie" przeszukiwać tekst. Jak jednak powiedzieć komputerowi, że "Roman" to imię męskie, a "Rumunia" to nazwa kraju? Gdyby tekst elektroniczny zapisać w piśmie sumeryjskim lub egipskimi hieroglifami, stosując wspomniane na wstępie determinatywy, byłoby to zadanie znacznie łatwiejsze, wymagające jedynie ustalenia konwencji dla jednolitego oznaczania różnych elementów. Nad problemem tym zastanawiano się już od lat 50-tych i przedstawiano szereg rozwiązań dla tekstów z różnych dziedzin, m.in. również humanistycznych, ale próby te nie uzyskiwały powszechnej aprobaty. Dopiero kiedy w 1967 r. W. Tunnicliffe zaproponował oderwanie wyglądu tekstu od jego treści - nastąpił przełom. Dwa lata później powstała pierwsza wersja Uogólnionego Języka Adnotowania Tekstu (GML - Generalized Markup Language) stworzona przez C. Goldfarba, E. Moshera i R. Loriego (których inicjały nieprzypadkowo są zbieżne z akronimem nazwy tego języka) dla korporacji IBM. Dalsze prace, prowadzone od 1978 r. przez specjalnie do tego powołany komitet American National Standards Institute (ANSI) - od 1984 r. również w ramach International Standards Organisation (ISO) - pod kierunkiem C. Goldfarba doprowadziły do opublikowania w 1986 r. oficjalnej normy ISO 8879 dla języka opisu tekstów elektronicznych - Standard Generalized Markup Language (SGML). Nie będziemy tu opisywać szczegółowo zasad SGML, ani tym bardziej możliwości i technik jego zastosowania [9]. Wystarczy powiedzieć, że jedną z aplikacji tego metajęzyka stanowi język HTML, któremu zawdzięczamy tak gwałtowny rozwój sieci World Wide Web (WWW) i praktycznie nieograniczoną możliwość publikowania tekstów elektronicznych dostępnych na całym świecie bez ponoszenia kosztów druku i oprawy przez wydawców - i bez konieczności kupowania drogich książek przez czytelników. Musimy jednak wyjaśnić samą istotę opisu elektronicznego jako najnowszego sposobu dostarczania badaczowi informacji metatekstowych i umożliwienia alinearnego dostępu do tekstu. Zgodnie z przyjętą przez twórców SGML i opartych na nim języków adnotowania koncepcją, każdy tekst składa się z hierarchii elementów (takich jak książka-rozdział-akapit-zdanie-fraza-słowo-sylaba-litera), u dołu której stoją encje (ang. entity), będące atomami tekstowymi (litery, cyfry, symbole, ilustracje). Aby opisać dany element, trzeba oznaczyć jego zakres i rodzaj, oraz ewentualnie podać dodatkowe informacje czyli atrybuty. Wprowadzenia takiej metainformacji do tekstu dokonuje się za pomocą znaczników (ang. tag), które mogą być odpowiednio zinterpretowane przez program komputerowy, w zależności od wymagań użytkownika. Moglibyśmy zatem przekazać komputerowi znaczenie słów z naszego wcześniejszego przykładu zgodnie ze standardem SGML w taki sposób: <nazwa typ="osobowa" podtyp="imię" rodzaj="męski">Roman</nazwa> <nazwa typ="miejscowa" obiekt="kraj">Rumunia</nazwa> Odszukanie w tak opisanym tekście wszystkich imion męskich czy nazw miejscowych nie będzie stanowiło już większego problemu. W pewnym sensie komputer będzie "rozumiał", że "Roman" to mężczyzna o takim imieniu. Oczywiście możemy w ten sam sposób wprowadzić informację o cechach gramatycznych tych samych słów, a także o dowolnych innych - większych i mniejszych - obiektach tekstowych. Ich przetwarzanie, analiza, formatowanie i czytanie będzie już jedynie kwestią wydania odpowiedniego polecenia algorytmicznego - niekiedy oczywiście o znacznym stopniu złożoności. Aby wydrukować sam tekst wystarczy "odfiltrować" wszystko, co znajduje się wewnątrz nawiasów. Ale możemy "poprosić" komputer o wydrukowanie nazw osobowych czerwoną czcionką albo zrobienie zestawienia wszystkich imion męskich w dwudziestym trzecim rozdziale. Odsyłacze do innych miejsc i innych dzieł zostały oparte na koncepcji hipertekstu - którego powstanie ma swoją osobną historię - i pozwala na natychmiastowe niemal dotarcie do właściwego ustępu tekstu znajdującego się fizycznie na innym komputerze lub innym kontynencie (co jest podstawą działania World Wide Web). Jak wspomnieliśmy, SGML jest metajęzykiem czyli zestawem reguł tworzenia języków opisu różnych rodzajów tekstu. Dla tekstów humanistycznych opracowany został taki właśnie język - a właściwie instrukcja wydawnicza dla edycji elektronicznych - pod nazwą Text Encoding Initiative (TEI). Inicjatywa ta rozpoczęła pracę w 1987 r., a obecna (trzecia) redakcja instrukcji opublikowana została w 1994 r. [10] Ustala ona standardową terminologię, zaakceptowaną przez większość liczących się wydawnictw i towarzystw naukowych. Nad rozwinięciem TEI dla celów edycji źródeł historycznych pracuje od 1995 r. Model Editions Partnership (MEP), w ramach którego współdziałają wiodące wydawnictwa źródłowe i uniwersytety.
 Instrukcja wydawnicza TEI została już wdrożona w bardzo licznych edycjach elektronicznych - głównie dzieł literackich, ale także wielu źródeł historycznych - i nie ma żadnego liczącego się konkurenta [11]. Dla badaczy-humanistów wychowanych na książce drukowanej adnotowany tekst elektroniczny może wydawać się przerażająco obcy. Pamiętajmy jednak, że to tylko zmiana konwencji - treść i istota edycji pozostają takie same. Współczesny rubrykator musi jedynie zamienić pędzelek i "terra rubrica" na edytor SGML i "terra electronica" - a glosy pozostają te same. Ani wspomnienia samego C. Goldfarba [12], ani inne relacje o powstawaniu SGML nie wspominają o piśmie klinowym, hieroglifach i determinatywach, ale podobieństwo podejścia do problemu jest uderzające. Po pięciu tysiącach lat zmagania się ludzkości z fenomenem tekstu powróciliśmy do tych samych rozwiązań - choć na zupełnie innym poziomie. Wszechobecność języka angielskiego w świecie komputerów stanowi również pewne nawiązanie do pisma hieroglificznego: jak słusznie zauważa D. Diringer, bowiem pisownia angielska tak bardzo różni się od wymowy, że wiele wyrazów jest prawie dowolnymi symbolami. [13] Przypisy [1]
D. Diringer, Alfabet, Warszawa 1972, s. 45-46.
|
||||||||||||||||||||||||||||||||
| |
|
|
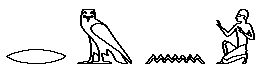 = Roman
= Roman
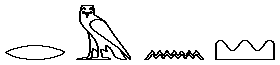 = Rumunia
= Rumunia